胡启滨科研周报12(2023-12-18至2023-12-24)

1. 摘要
本周主要是在补课程的大实验,阅读了两篇论文Text-to-3D Generation with Bidirectional Diffusion using both 2D and 3D priors和Text-Image Conditioned Diffusion for Consistent Text-to-3D Generation。
2. 具体内容
2.1 Text-to-3D Generation with Bidirectional Diffusion using both 2D and 3D priors
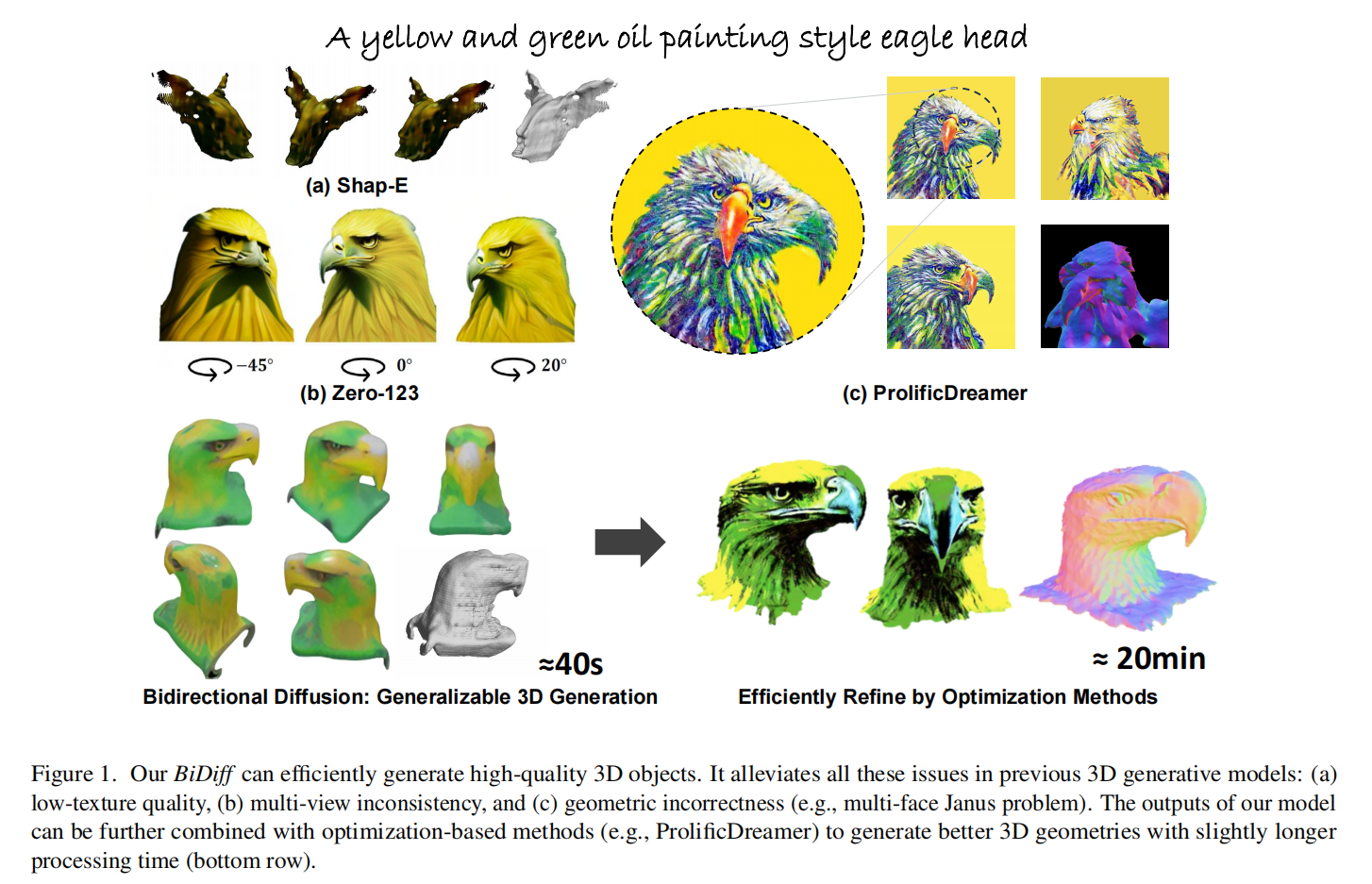
2.1.1 Contribution
针对此前text to 3d任务关注将2d生成模型升维到3D空间,并没有结合3D先验的情况。这篇工作结合2D diffusion和3D diffusion的先验, 能使生成的3D模型具有3D结构的高FID以及2D丰富的纹理信息。同时生成时间也从prolificdreamer的3.4h缩短到20min。
2.1.2 Method
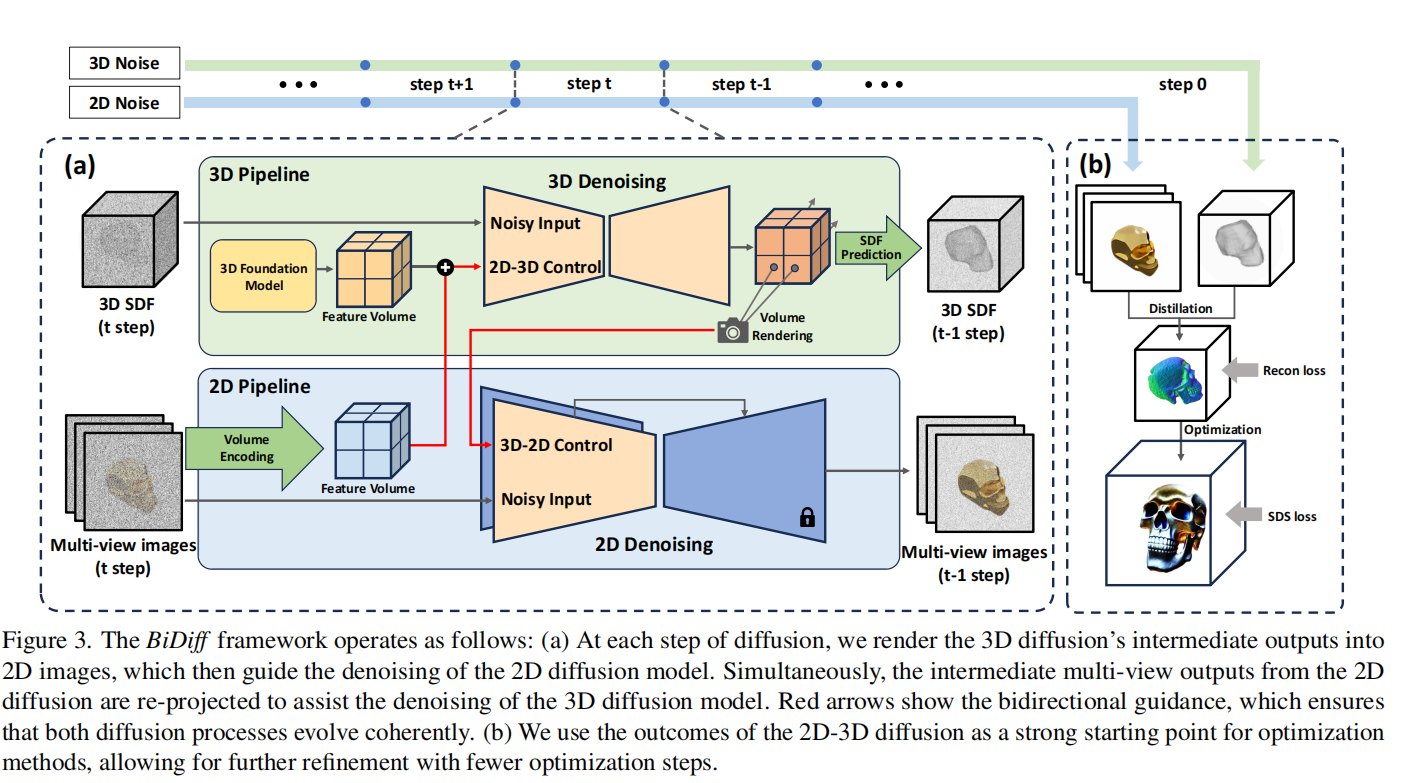
整个过程主要分为两大步骤:1.从3D Diffusion生成模型渲染出2D图片作为2D Diffusion降噪的guidence,从2D Diffusion中渲染的多视图作为3D Diffusion的guidence,这个过程体现了双向扩散。2.用3D Diffusion生成的SDF和2D Diffusion生成的多视图转化成Instant-ngp再进行进行后续SDS Loss优化。
Bidirectional Diffusion
3D Diffusion Model with 2D Guidance
2D Diffusion Model with 3D Guidance
Separate Control of Geometry and Texture
Optimization with BiDiff Initialization
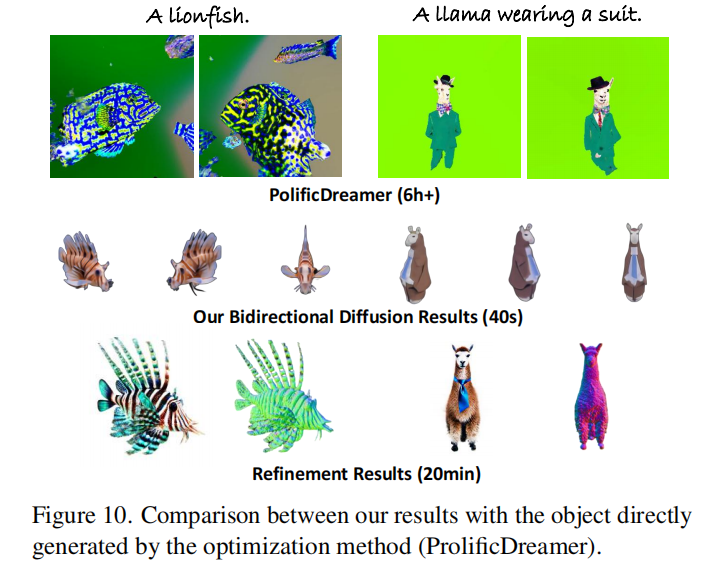
2.1.3 Results
2.2 (TICD)Text-Image Conditioned Diffusion for Consistent Text-to-3D Generation
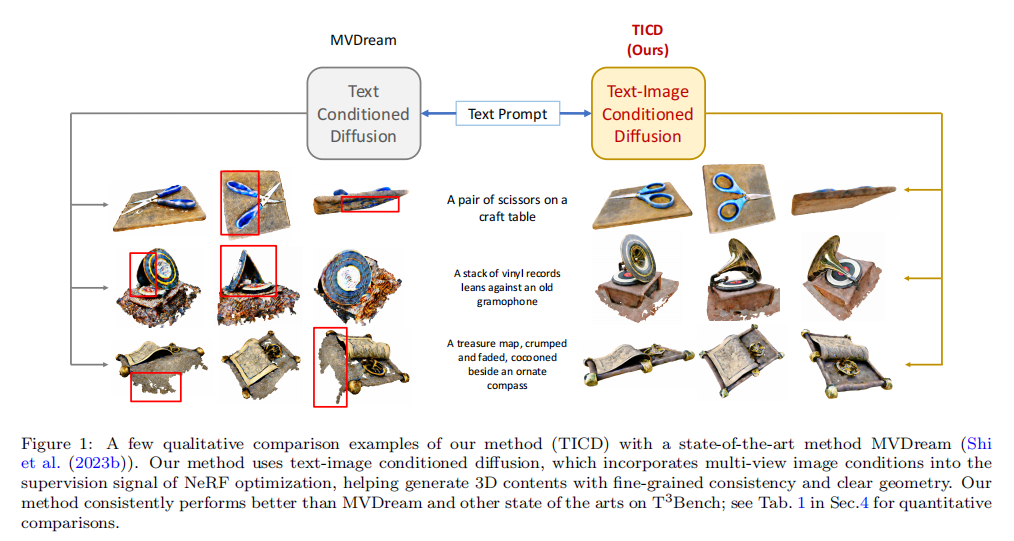
2.2.1 Contribution
TICD主要是对此前的SDS Loss进行了改进,此前的SDS Loss仅仅是对从NeRF中渲染出的图片与2D Diffusion基于text prompt生成的图片的Loss对NeRF进行优化,TICD则在此基础上新加了多视图条件,也就多了。能够实现精细的视图连续性和清晰的几何结构。
2.2.2 Method
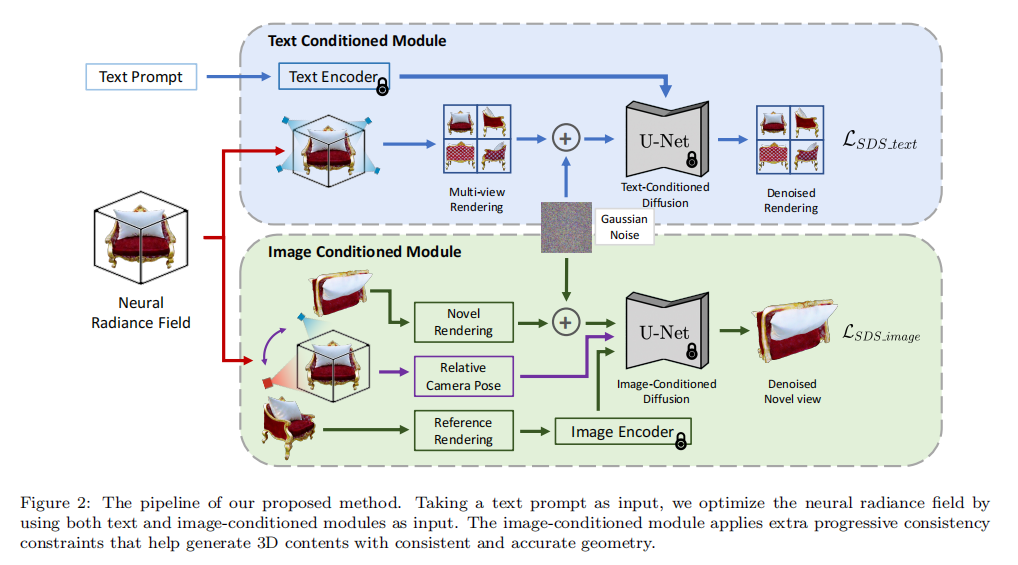
从Pipeline可以看出,相对于此前Text to 3D任务,TICD中新加了下面的Image Conditioned Module,也就多了这个模块的Loss,整个SDS Loss就变成了
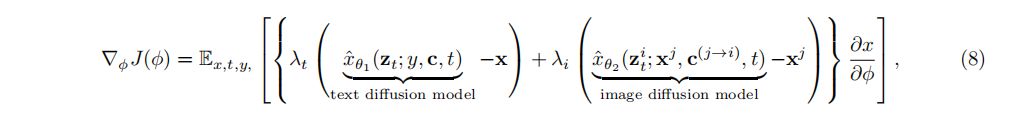
其中,和是两个Loss的权重。
2.2.3 实验结果

3. 存在的问题
- 这周还是在做课程实验,代码这方面跑的少。
- 还没有系统研究过目前Text to 3D任务的代码框架,现在只是大概了解每个模块能干些啥
4. 下周规划
- 看到NUS有一位老师就在这周系统地讲了video diffusion model,一个3小时的视频【视频扩散模型,三小时入门到精通,Mike Shou, Video Diffusion Models, 2023】,想在下周结合他的视频以及相关论文把video diffusion方向入门一下。
- 课程实验工作量有点大,还没干完,得继续弄。